
Does Intelligent Observability Need AI?
 By Liam Rogers,February 28, 2022
By Liam Rogers,February 28, 2022
Users should expect that their observability tooling will intelligently manage their machine data and make it easy for them to parse.
The Hype and Mystery of AI
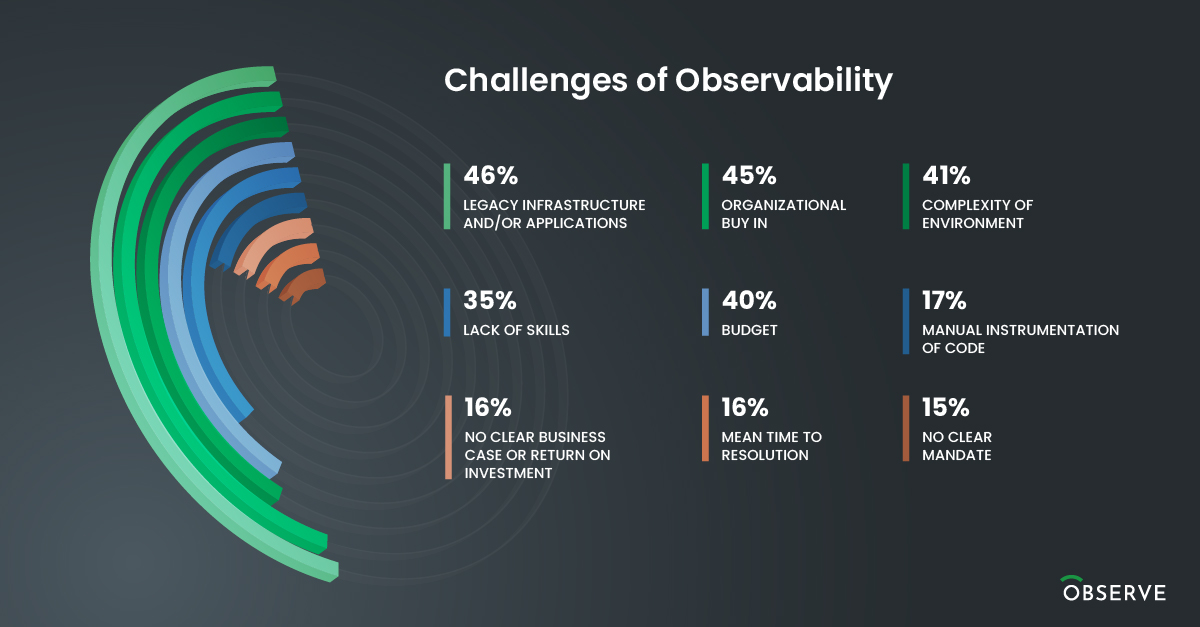
Buzzwords constantly come and go in our industry, but the hype and enthusiasm around AI has been slow to fade. Artificial intelligence (AI), machine learning (ML), deep learning, these terms still capture the imagination of many of us. In this time of unparalleled complexity, the concept of using AI/ML to augment IT operations and observability does have merit. In our last State of Observability report, 41% of organizations cite the complexity of their environment as one of the biggest challenges to observability.
It’s easy to see why practitioners hope that advances in ML and automation might offset that complexity and benefit them in their day-to-day tasks. However, the belief that everything can be made better by adding AI can lead to unrealistic expectations and overblown hype for current offerings.
AIOps isn’t a new concept and it’s been used to describe recommendation engines or predictive analytics used to improve maintenance and optimization of on-premises infrastructure and cloud resources. When added to monitoring and observability services the approaches from vendors thus far largely boil down to:
- Functionality baked into existing services to improve their efficacy and help reduce alert noise.
- A third-party overlay that attempts to correlate telemetry from multiple tools/sources to simplify root-cause analysis.
Baked-in functionality typically amounts to using ML – in a black box – as a recommendation engine that helps users dynamically set alert thresholds to improve the signal-to-noise ratio. The black box approach does little to build trust in the tool – a necessary precursor to allow more in-depth automation. As our co-founder and VP of Engineering Jacob Leverich would say, “Even if I built the perfect anomaly detector, I wouldn’t be able to explain the result without a lot of additional context.”
The lack of context for end-users continues to be an impediment to ML. Some vendors do offer more control and let users tweak or build ML models, but this can create more work for already overburdened teams, or teams that lack the necessary data science skills.
Machine learning is only as good as the training data it’s provided. As long as monitoring tool sprawl and data silos exist then AIOps tooling – usually built into o11y services – runs the risk of working off an incomplete dataset or with limited context. Tools that take the single pane of glass approach, i.e. ones that connect multiple monitoring tools to correlate events, can similarly have an incomplete view or at a minimum may be working off of sampled datasets.
Machine Learning ≠ Machine Intelligence
The reality is that we are years away from “self-driving” or fully autonomous operations. Achieving it would be dependent on automation advancements and not solely the inclusion of AI/ML – these technologies would need to work hand in hand. This highlights the disconnect between outcomes and methods and raises the question, “If we have intelligent automation and abstraction do we even need AI in the equation at all?”
If an outcome can be achieved without AI or ML then its inclusion is simply a vendor adding another checkbox to their burgeoning observability suites – without adding tangible value.
Thanks to the snowballing complexity in modern applications and infrastructure, it’s not too surprising that interest remains high in using ML when it comes to telemetry data. Aside from growth in complexity, the need is made even more acute thanks to personnel and skills shortages – thanks largely to the adoption of distributed architectures like microservices and Kubernetes.
The aforementioned State of Observability report showed that 35% of organizations indicate a “lack of skills” as a challenge to adopting observability. The growing number of unfilled SRE roles at companies of all sizes is indicative of the personnel shortage facing centralized observability.
Smarter tooling alone can’t solve all these problems, but it can help. Tooling need not be fully autonomous or AI-powered to make great strides over previous methods, such as the endless – and potentially fruitless – job of tagging machine data. In observability, intelligent grouping and curation of data is necessary to aid users in reducing noise and accurately correlate events without creating a mountain of additional work.
Users should expect that their observability tooling will intelligently manage their machine data and make it easy for them to parse.
How Observe Brings Intelligence and o11y Together
Adopting observability is a smarter approach to understanding machine data and rapid changes in IT environments. As far as having an impact on day-to-day usage, there are a myriad of practical ways that automation and abstraction can help users navigate their massive volumes of machine data – and without shoehorning in a neural net.
With Observe the responsibility doesn’t solely rest on the user to make sense of all the machine data, nor does it rely on ML as a method for cleaning up noise. Observe makes sense of collected telemetry through intelligent curation. When data is ingested it is automatically structured data into datasets that include Resources and Event Stream datasets. Resources are easily distinguishable “things” of interest, such as Nodes, Pods, or even users.
Observe was designed from the ground up to allow users to collect all of their observability data in one place (rather than separate silos) thus simplifying the correlation between events and resources from the onset.

Features such as the automatically generated dashboards – found on Resource landing pages – give users a set of useful metrics without having to build dashboards from scratch, while also allowing them to dive into the data behind the visuals. Looking at the big picture, GraphLink and Dataset Graph both let users visualize their environment and explore the relationships between datasets in a human-friendly way.
The combination of automatic structuring of data, auto-populating of dashboards, and graphs to turn telemetry into information means that users spend less time configuring their tooling and less time troubleshooting.
Observe does a lot on behalf of the user to turn their data into actual information, but human involvement is still needed to ensure the best usage of data. Users can create custom datasets as well as modify existing dashboards to tailor the experience to their needs. Observe automates the harder tasks to reduce toil and keep users from working “below the value line.”
Practitioners are right to demand that their tools get smarter as their day-to-day tasks get more time-consuming. Does this mean we all need fully autonomous and artificial intelligence-driven operations? No, often we need something more practical for day-to-day usage. Ultimately, using more intelligent tools is not about replacing humans, but removing hurdles so they can work more effectively.
If you or your company wants to take your observability strategy to the next level, we encourage you to start a trial or see a demo of Observe in action.