
Why Observe Chose to Build on Snowflake
 By Knox Lively,February 14, 2022
By Knox Lively,February 14, 2022
Engineers already have enough on their plate; we wanted to free them from meaningless work, and instead let their data work for them.
Observe, The Genesis
Few things were certain in late 2017 when our founders, along with seed investors at Sutter Hill Ventures, embarked on a journey to build a different kind of observability product. One thing we did know was that the three pillars model of Observability was dead – or at least dying.
At that time, products in the observability space hadn’t deconstructed data silos as promised, they simply re-arranged them. And worst of all, users were still left with piles of hard-to-read machine data. We wanted to do more than just bring users’ logs, metrics, and traces under one roof.
We wanted users to be able to ask questions about “things” they care about such as Pods, servers, and customers. But we didn’t want to stop there; we wanted to show how these “things” were related, and how they changed over time – all without spending countless hours pre-processing data or designing elaborate tag schemes to make their data useful. Engineers already have enough on their plate; we wanted to free them from meaningless work, and instead let their data work for them.
To The Drawing Board
After months of iteration, deliberation, and consideration we found that the fewer opinions we had about customers’ data, the better. However, we knew two things for certain:
- Users should be able to send us a wide variety of machine data from a diverse range of commodity collectors like Fluentd, Logstash, and Prometheus.
- We wanted to create highly informed relational models of all of this data and turn it into actionable insights.
But before the first line of code could even be written, we had to find – or build – a database that could handle our big dreams. Ultimately, there was a reason why a product like Observe didn’t exist in the marketplace – it was hard. We’d need to come up with a laundry list of features we’d need if Observe was ever able to come to fruition.
Our founding idea, to take users’ machine data and turn it into useful “things,” meant we needed to be able to merge – or join as it’s referred to in SQL – two very different types of data commonly used in the industry. This “marriage” of different data types is the core of Observe, and how we’re able to provide context and insights from traditionally disparate datasets to our users.
Data types needed for Observe Datasets:

To unite these different types of data, we needed a database that could work efficiently with semi-structured data. We had to be prepared for any type of data customers threw at us. After all, logs are not known for their uniformity, nor could we predict every scenario and data-type customers would send to us.
We knew what types of data we would use, but we also needed to handle large amounts of data – terabytes or petabytes per day, stored for years – all with industry-leading data security standards. Easy enough, right?
Lastly, we envisioned a pricing model that would allow users to store their data dirt-cheap [near S3 cost] and only pay when they use [query] that data. We had no interest in handcuffing users to a flat, per-annum, pricing model that offered little or no flexibility. We’d learned from our competitors – customers don’t fancy white-collar ransomware.
Build vs Buy
With our requirements in hand, we found ourselves at a crossroads. It was time to decide the age-old engineering question of “build vs buy.” As usual, there were considerable tradeoffs with either approach.
In the build corner, we could have every feature we desired, guaranteed integration with other products and services, as well as total control of the entire development process. The cons associated with building, however, were significant. Our founders knew from experience that it would take a team of database development experts an average of four years to build the basic database engine alone. We had the opportunity to create a product that could usher in a huge change to the way people approached observability. Four years seemed like a lifetime to us.
As our co-founder Philipp Unterbrunner put it,
We don’t want to spend four years creating another database, we want to build a product.
The decision was clear. Rather than building our own, we’d purchase an off-the-shelf database and integrate it. Though, adopting third-party technologies can be a double-edged sword. For starters, there would be numerous engineering constraints along the way – something which can be surprisingly healthy for innovation.
After a two-year-long incubation and benchmarking period, considering a handful of open-source and commercial systems, we found Snowflake met all of our requirements and more.
Snowflake, A Primer
Even for those outside of the tech industry, Snowflake has become a household name. Part of the fandom has its beginnings in their monumental IPO, held in September of 2020, which still holds the record as the biggest software IPO to date – netting them a market valuation of $70.4 billion by the end of its very first day of trading.

Though Snowflake may be a household name, many don’t fully understand the technology or grasp its impact on the way people now analyze data and use it to build data analytics tools.
In 2015, Snowflake entered the market with a cloud-based storage and analytics service they referred to as the “Data Cloud.” At the core of the Data Cloud vision is a high-performance relational data warehouse with a standards-compliant SQL interface – all packaged as a slick, pay-by-use SaaS product.
Their products’ secret sauce is that it separates compute and storage resources to give users the right balance between performance and cost. This “data liberation” of sorts, gives Snowflake users the ability to use their data when and how they want to, which has fueled its widespread adoption as a service. Many of the world’s largest companies – Capital One, Dropbox, and DoorDash to name a few – use the Snowflake platform in their daily operations.
Okay, But WHY Snowflake?
To put it simply, the Snowflake platform met all of our requirements and the flexibility of the platform was directly in line with our ethos – to give users valuable insights into their observability data with as few opinions as possible.
Requirements [revisited]:
- The economics must make sense for our use-case.
- Must work efficiently with semi-structured data.
- Efficiently execute joins on large volumes of different types of data
- The ability to ingest terabytes [and in the future, petabytes] of data per day, and then store that data for months, to even years at a time.
Snowflake Economics:
Whether it be fate, destiny, or luck, the Snowflake architecture – namely the separation of compute resources and storage – aligned perfectly with our pricing model.
Snowflake’s pricing model only charges users for the amount of data they store, and when they analyze it. This allowed us to stay true to one of our founding principles, to deliver a product that gives users the flexibility to use it when and how they see fit – without feeling constrained by inflexible and costly contracts.
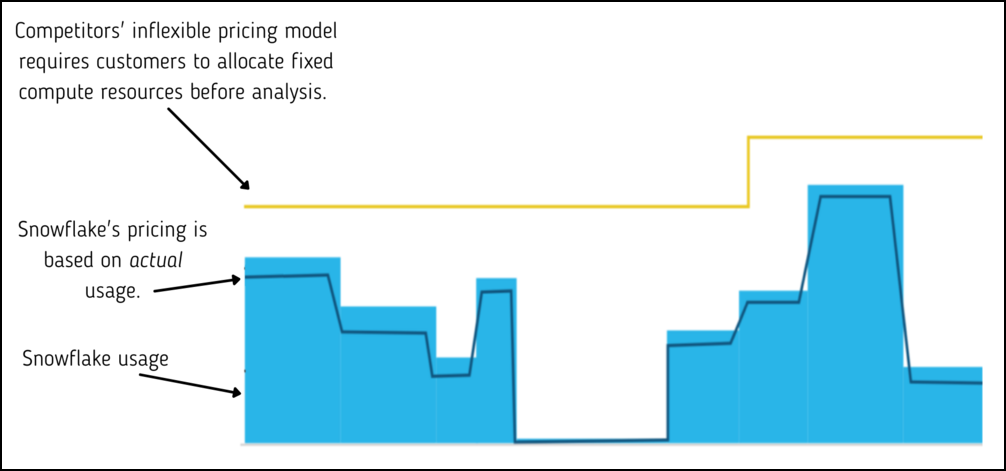
On the storage side, this means that our users can simply dump all of their observability data into our platform and store it at low S3 costs. They can then ask questions at a later date as their observability practice matures, and they better understand the metrics and measures they care about.
When it comes to the economics of analyzing their observability data, users benefit directly from the economies of scale that Observe can provide. Utilizing Snowflake’s multi-tenant architecture, Observe can dynamically batch queries from across many customers to cut down on compute waste – resulting in lightning-fast, and efficient queries.
Semi-Structured Data:
Support for semi-structured data was paramount to the success of our product. After all, we wanted users to see Observe as a one-stop-shop for all of their observability data. Snowflake allows our users to send any, and all, of their observability data to Observe without having to spend hours pre-processing, tagging, and indexing their data before they can use it. As our CEO, Jeremy Burton would put it, this pre-processing of data is work below the value-line. But we can take that a step further to say: not only is this work meaningless, but it also detracts from real work.
Joins:
Coincidentally, we found that Snowflake was excellent at executing large joins and group-bys. These operations are crucial to combining the two very different types of data we need to bring context to mounds of users’ machine data, or simply put, joins allow us to show how various datasets are related – without any input from the user.
Besides the obvious benefits of abstracting out resources from piles of data, this merger of two data types allows us to show customers – visually – the relationship between their datasets to give them a thirty-thousand-foot view of their observability data.
Ingest And Store Large Volumes of Data Without a Hiccup:
Lastly, Snowflake allows Observe to manage an enormous amount of data daily. On average, we ingest nearly a Petabyte of customers’ observability data each month – and that number continues to grow.

And because Snowflake separates compute and storage, this allows our users to store all of their machine data for months, if not years at a time, without worrying about incurring usage costs.
Due to inflexible software architecture, many – if not most – vendors in the Observability space by necessity have such restrictive pricing models that users often have to choose which observability data they collect, and they often store it for much shorter periods than users would like. In the event of an audit – or, science forbid, a data breach – companies may find that their data is simply not there. Thanks to Snowflake, we’re able to pass down these cost benefits so users don’t have to make hard decisions about their data.
Bonus Round
Besides checking the boxes from our database shopping list, Snowflake brings with it a host of other benefits. For starters, the sheer flexibility of the platform allows us, and our customers, to pivot when necessary.
Georgios Giannikis, one of our Principal Engineers, is a big fan:
The fact that in a couple of seconds [with Snowflake] you can add more compute without setup of any kind – you don’t need to copy data from one place to another, or preload a computer with more data – this is invaluable.
Most importantly, the fact that Snowflake is a SaaS platform means much lower overhead in terms of cost, time, and management. This allows us to spend all of our development efforts on building a next-in-class observability product, rather than first spending years upfront designing and building a database.
It also means that we don’t have to hire a team of database administrators, SREs, or DevOps Engineers to manage all the infrastructure that comes along with developing an enterprise data management system.
Observe + Snowflake = The Future of Observability
The adoption of the Snowflake platform made it possible for Observe to deliver on our “founding charter” – to provide our users with useful insights from their seemingly disparate and neverending mounds of machine data. We go beyond giving users a portal where they can simply store and manage all of their data, we thoughtfully curate their data into useful insights, show how it’s related, and free them from meaningless work so that they can build their great product.
If you and your team want to take your observability strategy to the next level, we encourage you to check out our demo of Observe in action. Or, if you think you’ve seen enough and want to give Observe a spin, click here to request trial access!