LLM Observability
Monitor and optimize your AI applications with complete visibility into performance, costs, and behavior. Track every LLM request and agentic workflow without the blind spots that cause critical AI application issues to go undetected.
AI Application Tracing
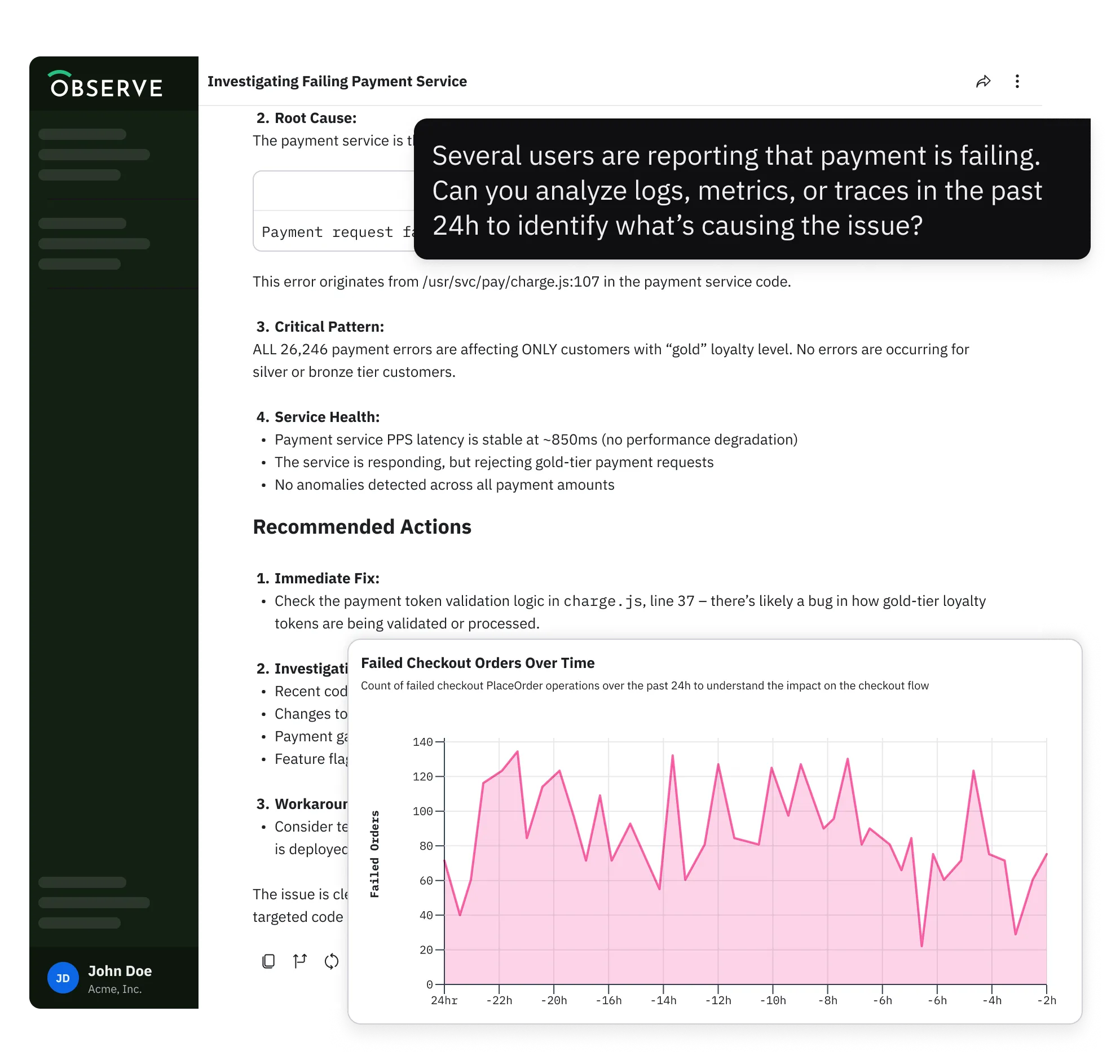
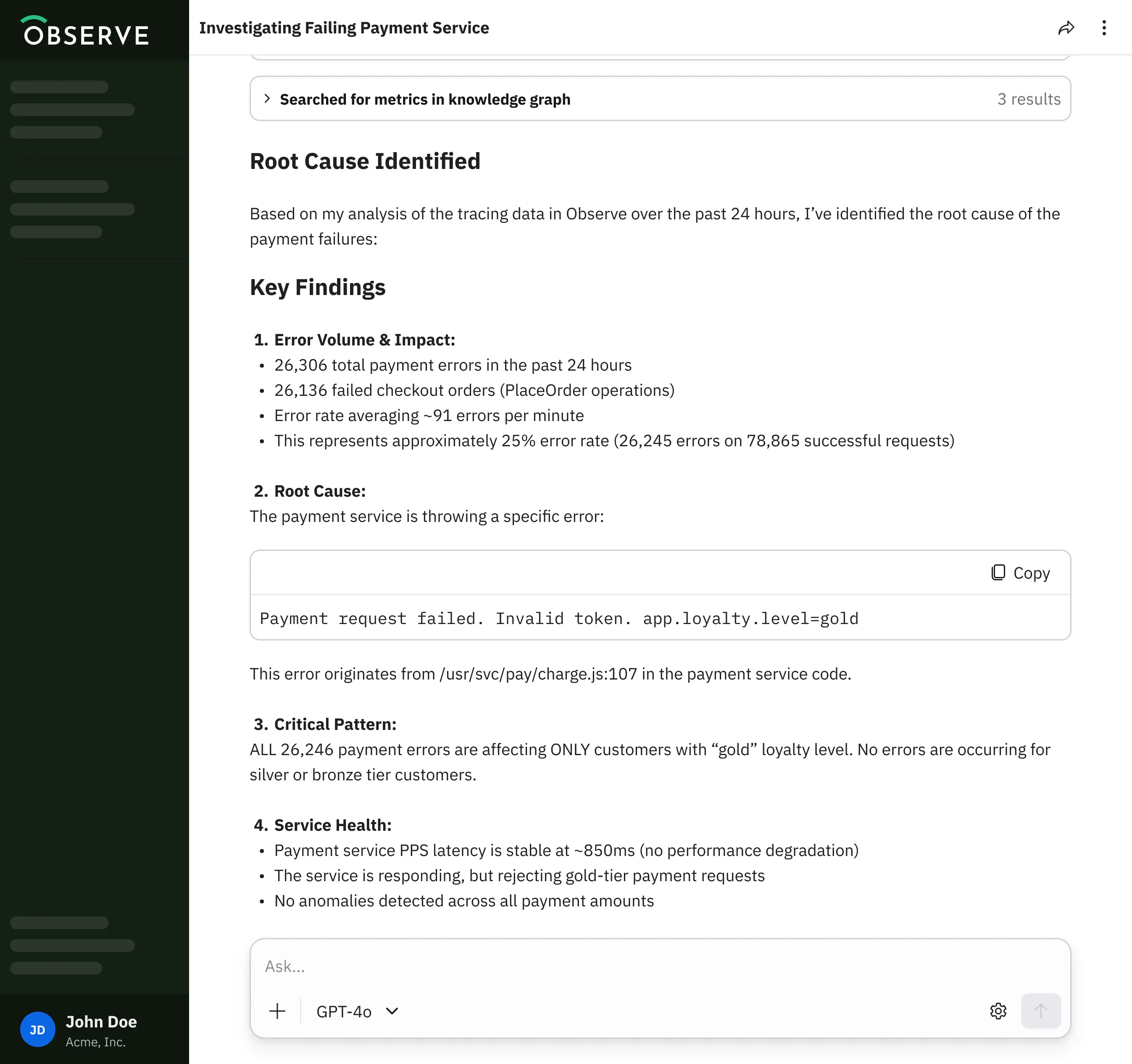
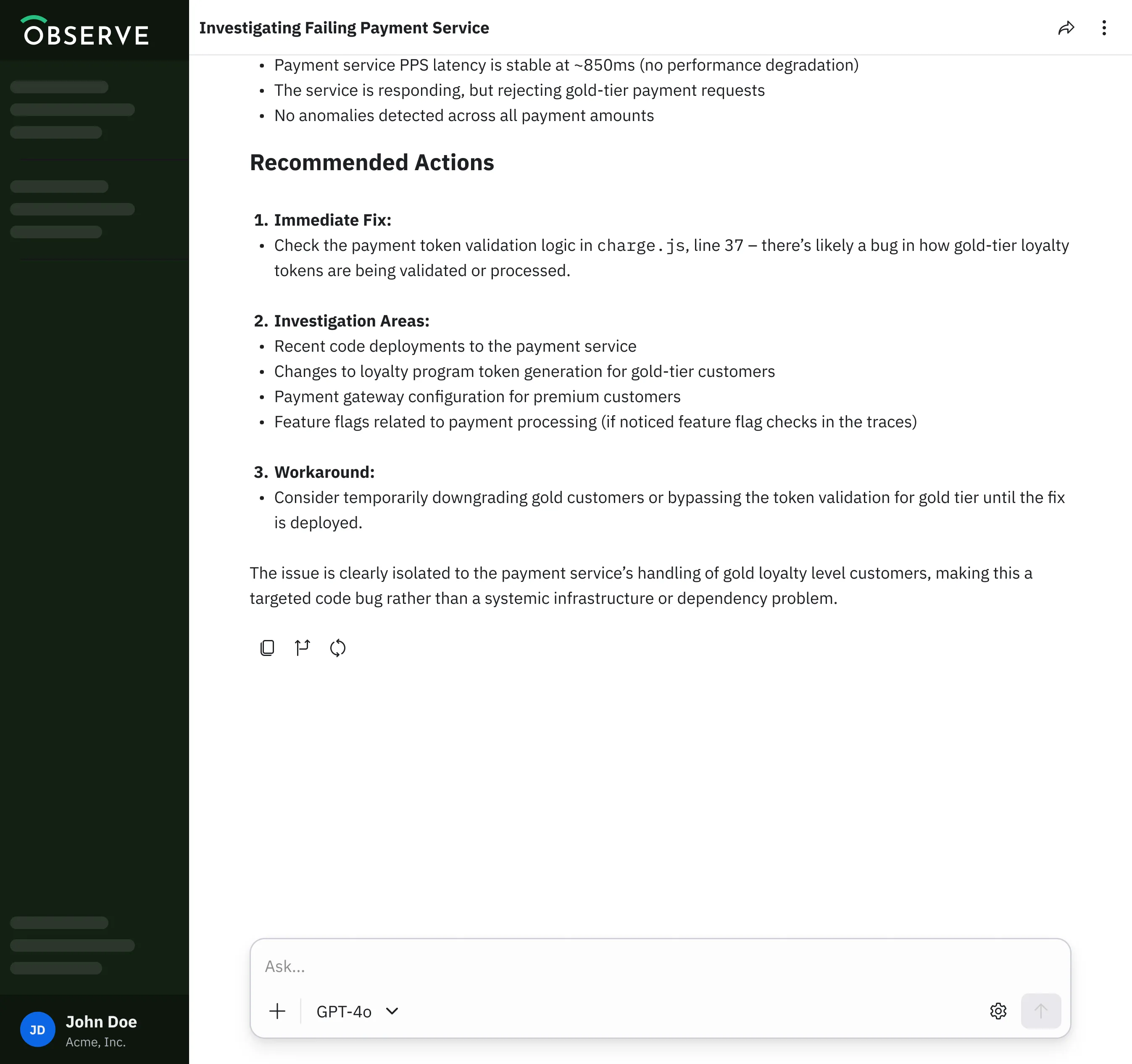
What’s the status of API Server in prod? Do we have a memory leak?
Cart service shows a latency spike from 12:00 PM PT. What changed between then and the previous 30 minutes?
Create a monitor for payment service 5xx HTTP error responses.
Complete Workflow Visibility
Trace multi-step agentic workflows from user prompt to final response without sampling that could miss critical failure points in complex AI reasoning chains.
Cross-Infrastructure Correlation
Connect AI application performance to underlying infrastructure and services in one platform, eliminating manual correlation across separate monitoring tools.
Full Request Capture
Retain complete LLM trace data with long-term storage so your entire team can investigate issues retrospectively without access restrictions.
Observe’s AI SRE and MCP Server have the potential to transform how we investigate incidents and reduce the time engineers spend on resolving issues by providing faster, more contextual insight into system behavior.
It’s a major unlock for our SRE practice, empowering teams to proactively analyze systems and address potential issues before they impact players.
Observe's AI SRE knows more about my products and services than my best engineers at this point and I can prove it. The level to which this is going to transform my tech team is unimaginable at this point.
- Financial Services Institution
AI Application Tracing
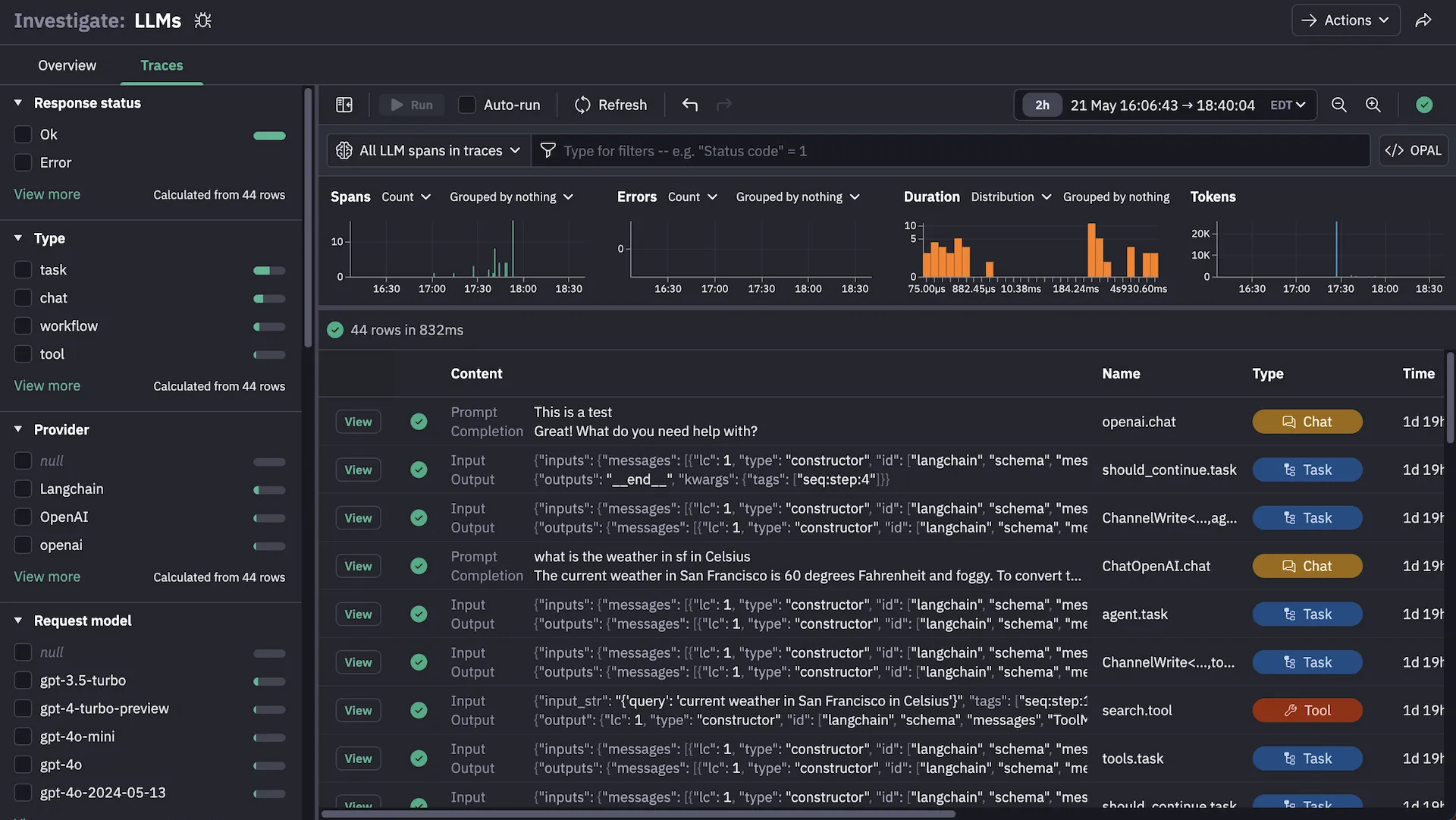
Complete Workflow Visibility
Trace multi-step agentic workflows from user prompt to final response without sampling that could miss critical failure points in complex AI reasoning chains.
Cross-Infrastructure Correlation
Connect AI application performance to underlying infrastructure and services in one platform, eliminating manual correlation across separate monitoring tools.
Full Request Capture
Retain complete LLM trace data with long-term storage so your entire team can investigate issues retrospectively without access restrictions.
AI Application Tracing
Complete Workflow Visibility
Trace multi-step agentic workflows from user prompt to final response without sampling that could miss critical failure points in complex AI reasoning chains.
Cross-Infrastructure Correlation
Connect AI application performance to underlying infrastructure and services in one platform, eliminating manual correlation across separate monitoring tools.
Full Request Capture
Retain complete LLM trace data with long-term storage so your entire team can investigate issues retrospectively without access restrictions.
Cost and Token Analytics
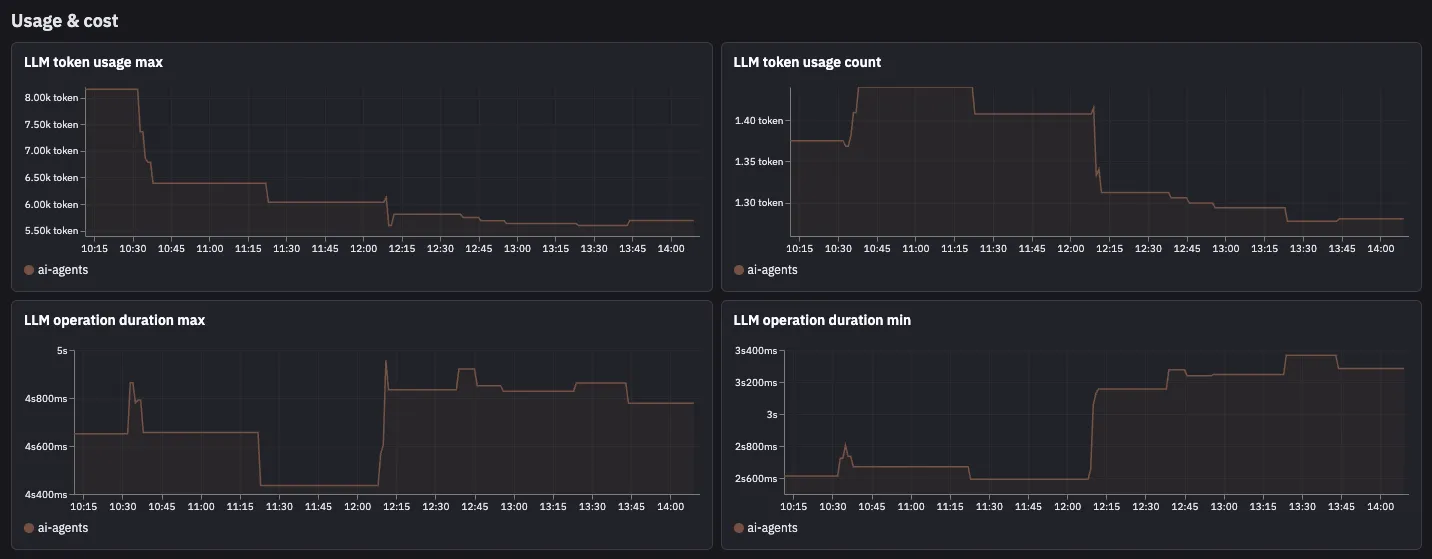
Real-Time Cost Tracking
Monitor API spend across all LLM providers in real-time to prevent budget overruns and identify cost spikes as they happen.
Token Usage Breakdown
Analyze input and output token consumption by model, provider, and application feature to identify optimization opportunities and usage patterns.
Provider Cost Comparison
Compare token costs and performance across different LLM providers with detailed metrics to make informed decisions about model selection and routing.

