Log Management
Search and analyze event data across your applications, infrastructure, security, or business without worrying about indexing, data tiers, retention policies, or cost. Keep all log data always hot.
Quick and Easy Setup

Get Started Quickly
Quickly get started with collecting logs across your entire stack using OpenTelemetry Collector, FluentD, FluentBit, cloud, containers, Kubernetes, serverless, and over 400 integrations.
Ingest Log Data
Ingest log data in any format – structured, semi-structured, or unstructured from any data source. Scale as you need on-demand. Observe is designed to handle log bursts. No need to create log buffers or pipelines.
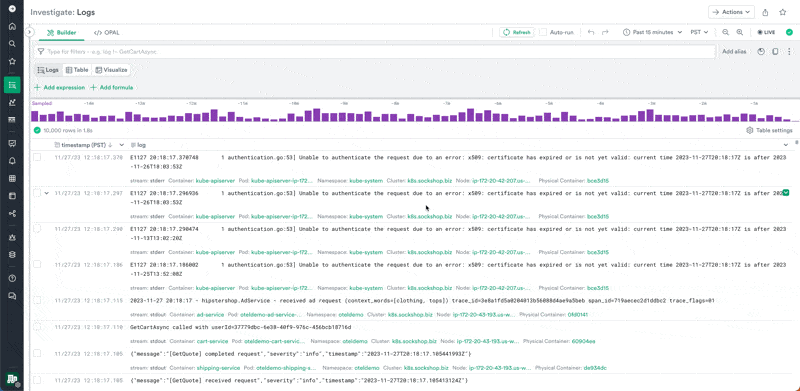
Explore Log Data
Explore log data using Query Builder or OPAL, a feature-rich query language to explore and transform data. Use O11y Copilot to generate OPAL.

Faster Troubleshooting

Troubleshoot Issues in Real Time
Use Live Mode for detecting and troubleshooting issues in real-time.
Analyze Log Data
Search, filter, and analyze log data using intuitive query builder or using feature rich OPAL to enrich and transform event data.
Correlate Logs from Any Source
Correlate logs from any source using correlation tags and pre-built relationships. Pivot to logs from dashboards or trace explorer for faster root cause analysis and troubleshooting.

Log-Derived Metrics

Derive Custom Metrics
Derive custom metrics based on specific log attributes, patterns, or content that are relevant to your business objectives.
Extract Any String
Extract any string from the log message using point-and-click UI and O11y AI Regex for faster analysis.
Generate Unlimited Log Metrics
Generate unlimited log-derived metrics for longer retention and analysis at no extra cost.
Zero-Compromise Compliance
Achieve Compliance
No trade-off between performance and cost for long term retention of logs. Achieve compliance readiness by keeping logs for as long as needed at the nominal additional cost of $0.01 per GiB/month.
Keep Data Hot
All data is always kept hot. Eliminate toil of moving data around or creating data tiers for hot, warm, cold, or frozen tiers.
Access Historical Data
Access historical data on demand to satisfy compliance requirements.


