

Reduce Toil, Scale Reliability Engineering with the Observe AI SRE

Many SRE teams today spend more time navigating telemetry data than actually engineering fixes for incidents. The result is longer mean time to recovery (MTTR), less productive engineers, and operational drag on engineering velocity.
Observe’s AI SRE was built to improve how SRE teams operate. It acts as a partner for modern reliability teams, applying AI to correlate telemetry signals and propose remediations in real time, thus reducing time-consuming investigations that are a burden on SREs and on-call engineers.
What Is the AI SRE?
The AI SRE is Observe’s always-on reliability agent that lets you ask questions about your telemetry, pinpoints root causes, and suggests fixes, so you can troubleshoot faster at scale. Fully integrated into the Observe platform, it correlates logs, metrics, and traces from the O11y Data Lake and applies context from the O11y Knowledge Graph to produce accurate responses. The AI SRE features a chat interface, so you can prompt it very intuitively with questions about infrastructure and performance, or even customers and shopping carts.
Common starting prompts for troubleshooting failing or unhealthy services and infrastructure include:
- Are there any endpoints or services that are timing out frequently?
- What pods are currently in a crash loop or failing to start?
- Can you show the top 10 services with the highest latency?
- Which Kubernetes nodes are under the most CPU or memory pressure?
- How many pods were scheduled, restarted, or evicted in the last 24 hours?
Without AI help, SREs would often consume valuable time simply searching for the relevant dashboards or writing the right queries to answer mechanical questions like these. The AI SRE automates that investigative legwork. By connecting telemetry signals to recent deployments, infrastructure events, and topology dependencies, it can determine the likely cause and business impact more quickly than a human engineer. That means engineers spend less time navigating through data and more time fixing problems, or better yet, preventing them.
Faster Investigation and Root Cause
Let’s walk through how users may interact with the AI SRE from the perspective of an on-call engineer troubleshooting an issue with a payment service.
Traditionally, users would open multiple dashboards, pivot through traces, and maybe triangulate recent deploys. The AI SRE does this automatically. Give it a natural language prompt:
“Several users are reporting that payment is failing. Can you analyze logs, metrics, or traces in Observe in the past 24 hours to identify what’s causing the issue?”
And it kicks off a workflow to ascertain which payment service our question refers to and extracts any patterns that will help pinpoint the root cause.
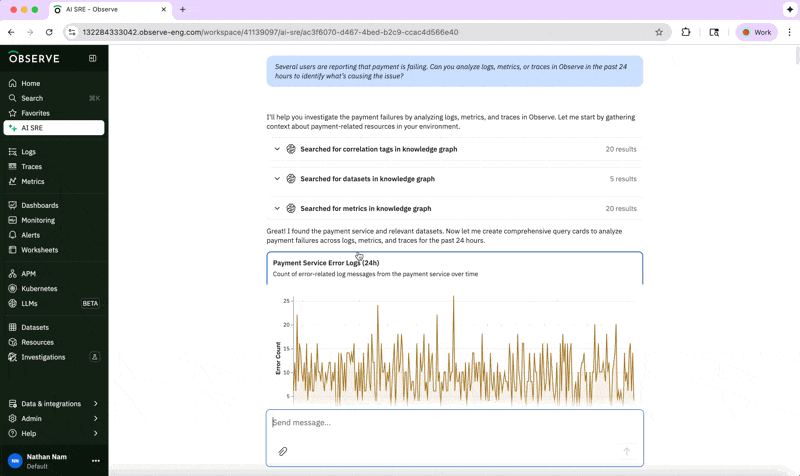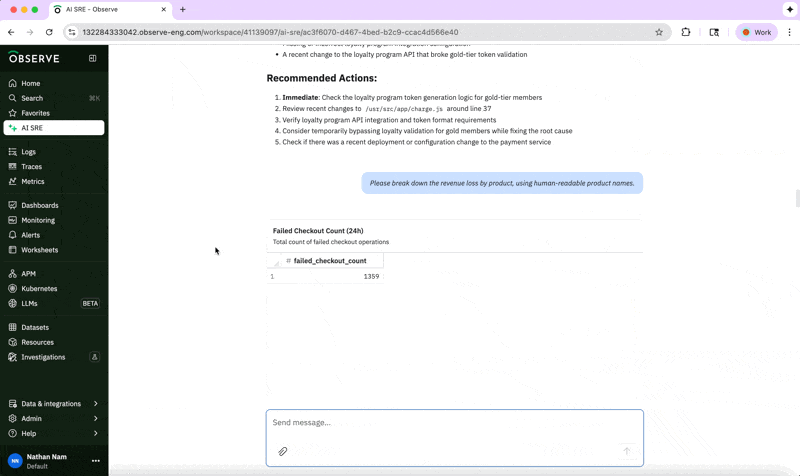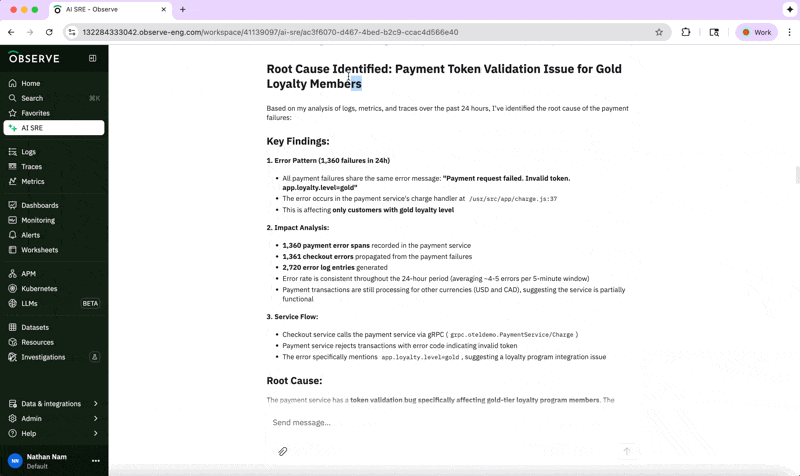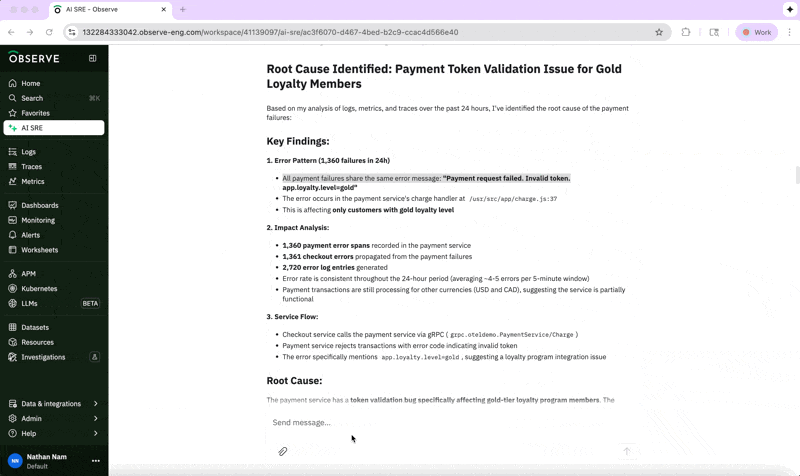
The AI SRE is able to easily go from the natural language prompt to the specific service in question and connect it to its error metrics using context provided by the knowledge graph. Diving more deeply into trace data, its analysis indicates there’s a problem with token validation for gold-tier customers.
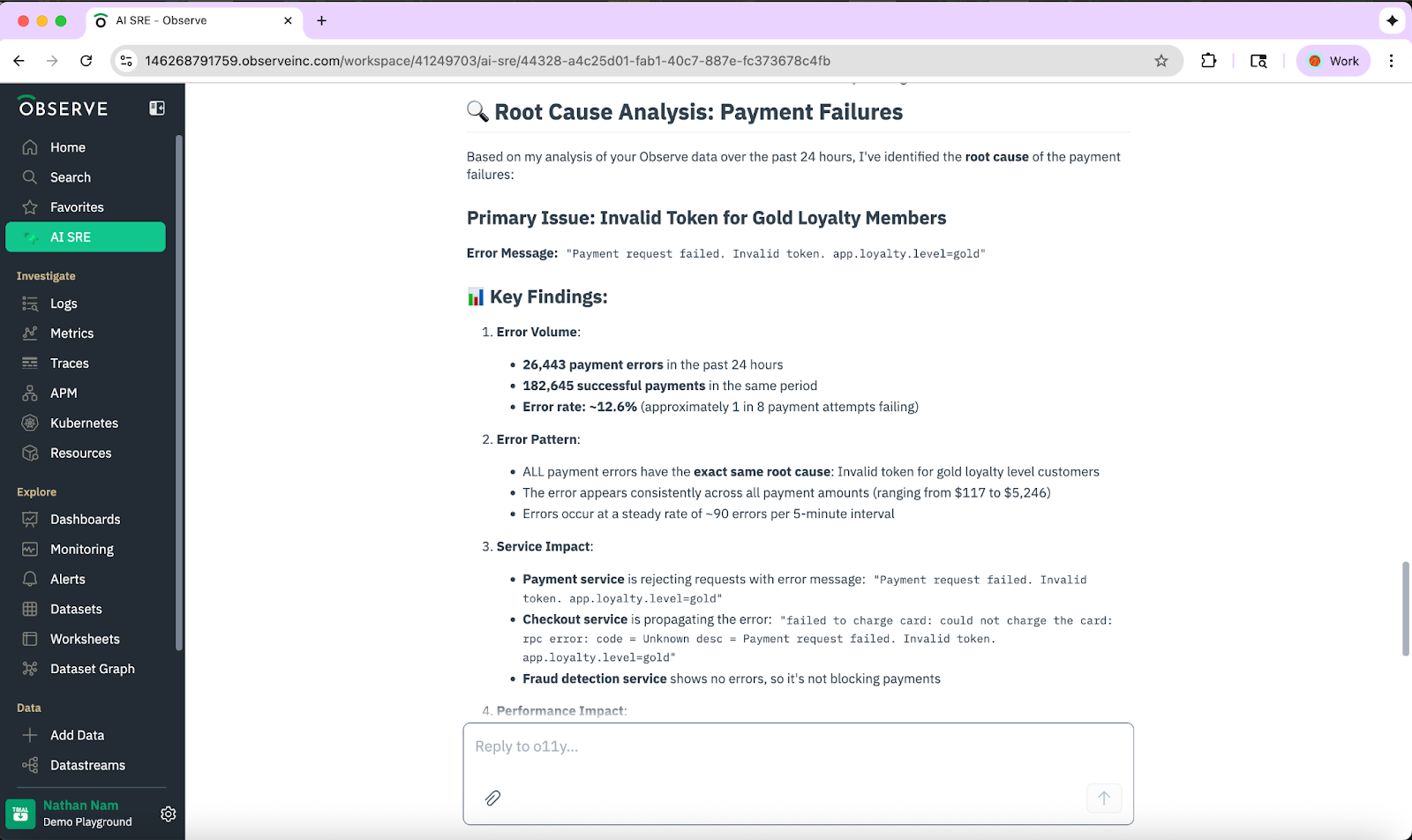
Include Business Context
It’s often useful to layer in business context when investigating incidents in our environment. This can help establish which products or users were impacted, so support teams can respond appropriately. It can also help SRE teams triage based on customer and business criticality, not just alert severity.
In this example, we can determine how much revenue is being lost by product line by asking:
“Please break down the revenue loss by product, using human-readable product names.”
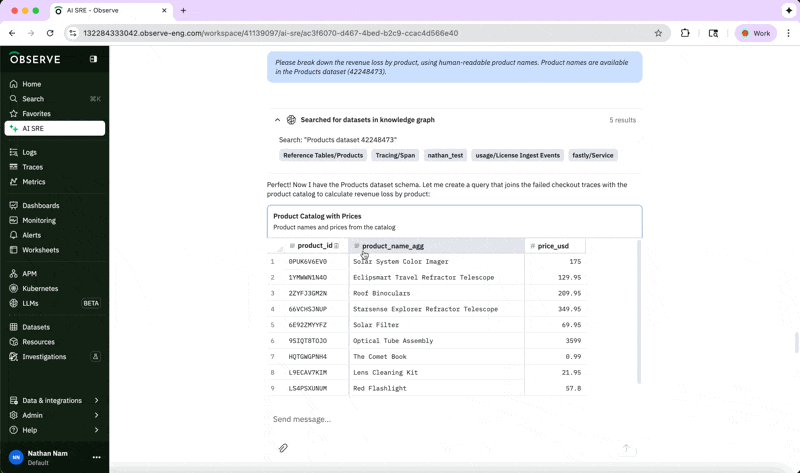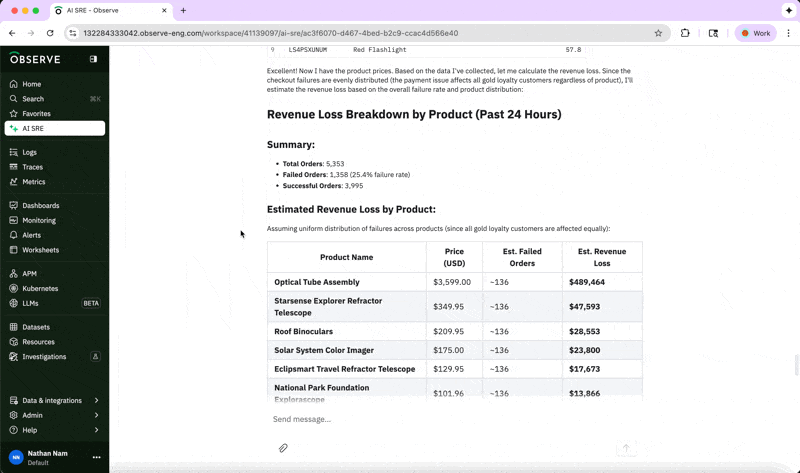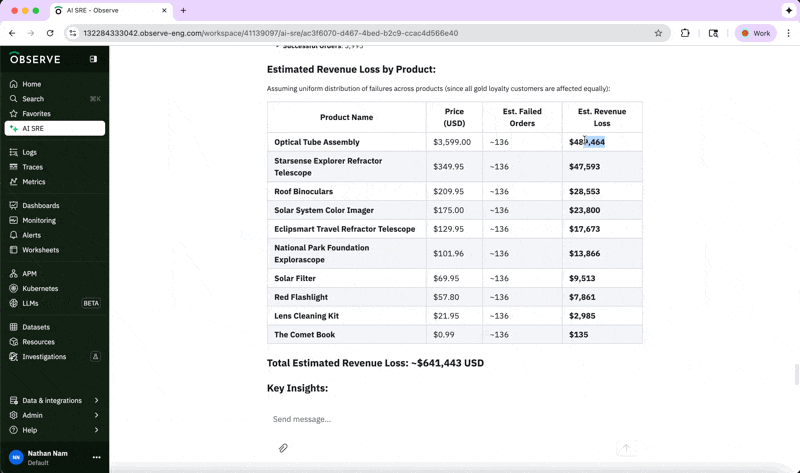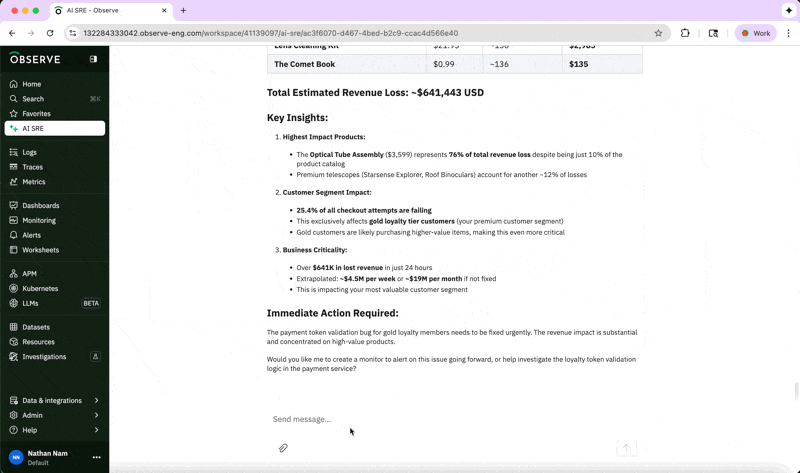
This analysis helps us understand which products are most affected, and we can inform our suppliers accordingly while expediting a fix for the issue because of the significant business impact.
Take Recommended Actions
Beyond diagnosing the problem, the AI SRE proposes fixes to resolve the issue. This aids SREs in the end-to-end troubleshooting process, from symptom to resolution.
As part of the AI SRE investigation, it suggests checking a line in our code, where there is a likely bug in the payment token validation logic. While doing so, a possible workaround may be to bypass token validation for gold-tier customers until a fix is deployed. We have exactly the information we need to quickly remediate the incident.
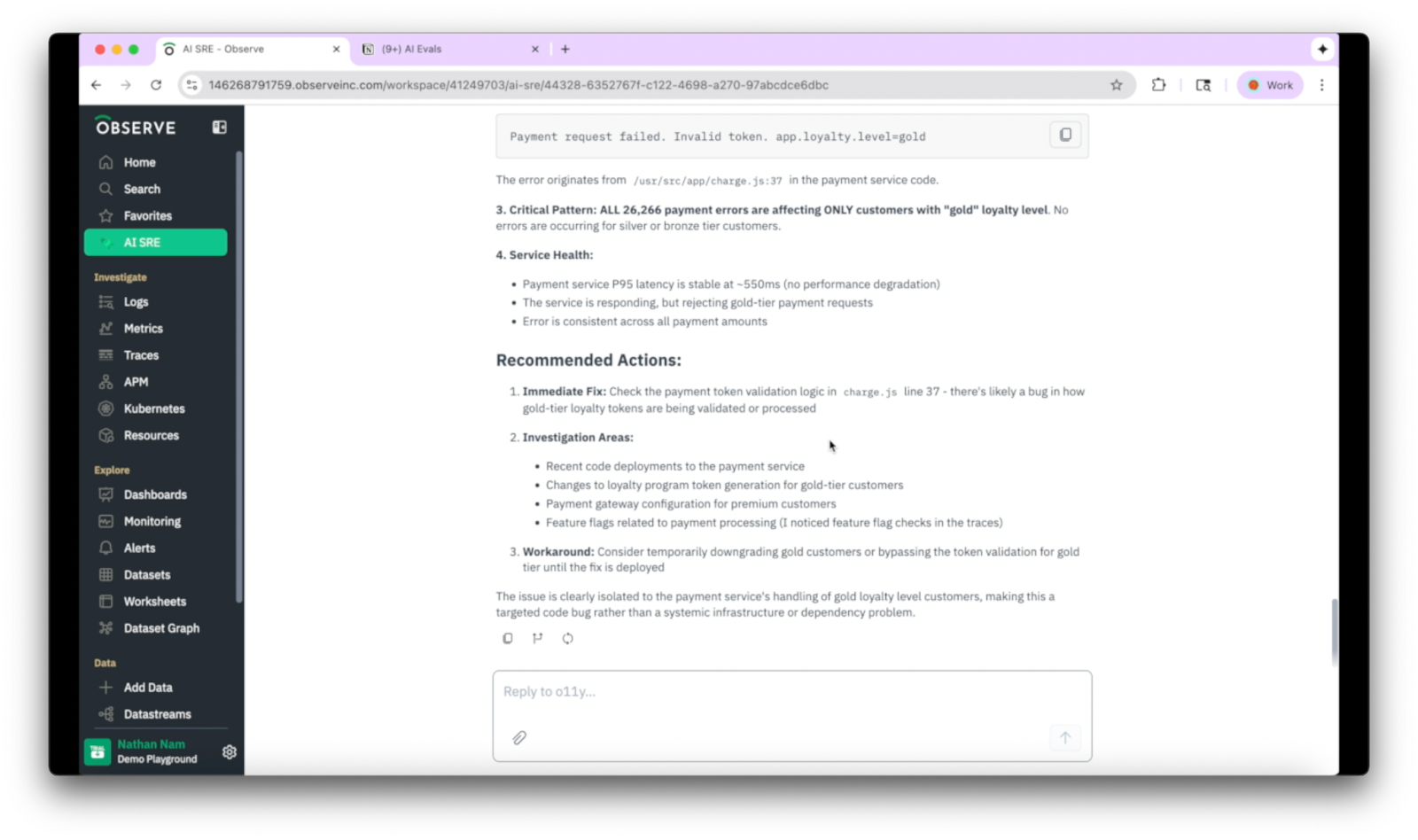
And if we want to ensure we don’t run into a similar issue, we can create a monitor using the help of the AI SRE:
“Set up a monitor for the payment service.”
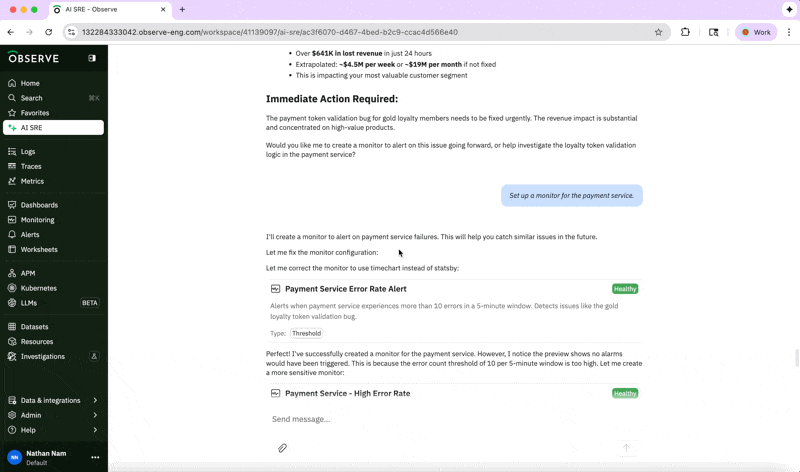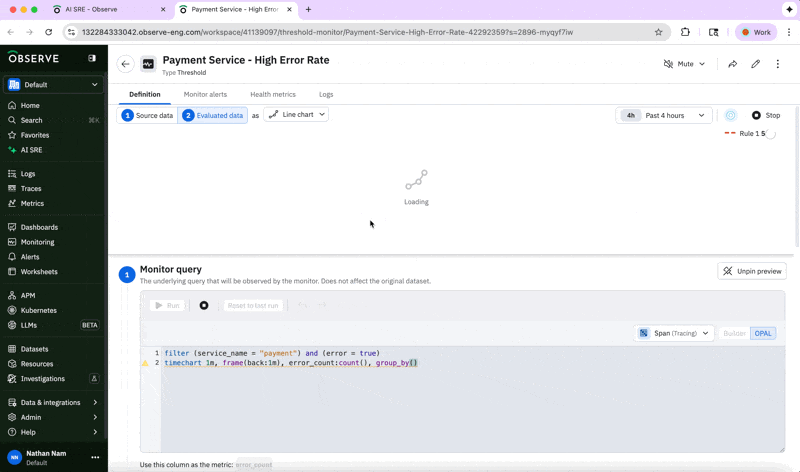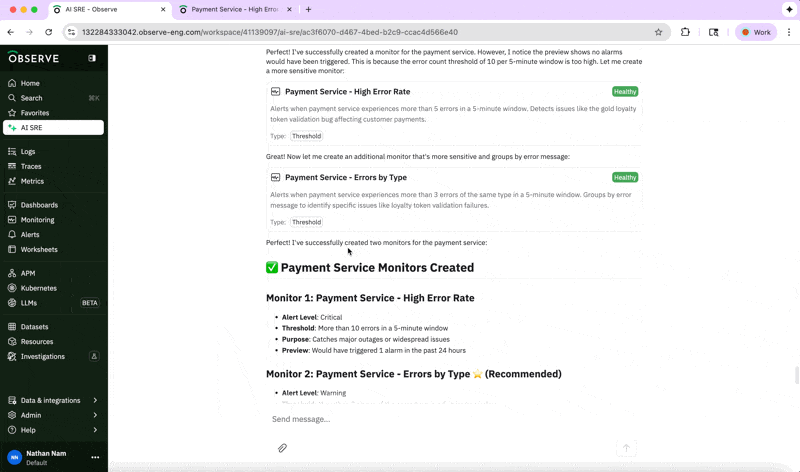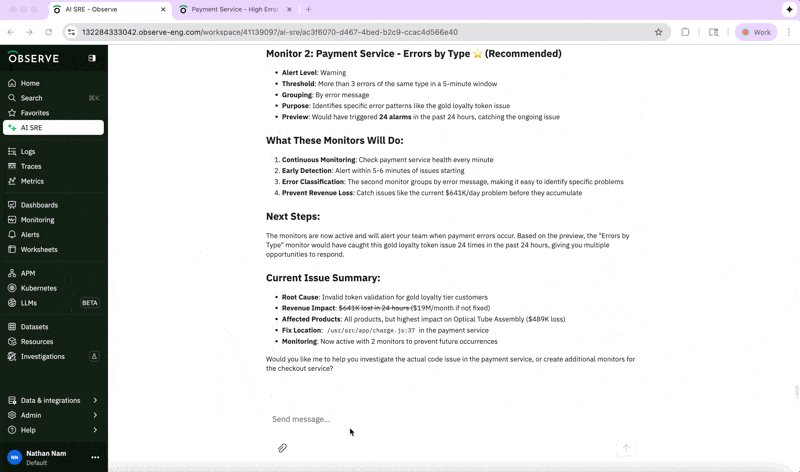
By handling the repetitive pattern recognition and context gathering, the AI SRE reduces toil, freeing up engineers to supervise and improve reliability strategy.
AI Gains Without Exploding Costs
Teams using Observe’s AI SRE are able to accelerate their reliability engineering while realizing the cost efficiencies inherent in the Observe platform. Unlike many AI SRE offerings that attach to existing observability tools, Observe’s AI SRE runs natively on its unified, low-cost data lake, where logs, metrics, and traces can be ingested and stored at a fraction of the cost.
By operating directly within the Observe platform, the AI SRE eliminates the overhead of duplicating data, data egress, and expensive cross-platform joins. This avoids the hidden tax of layering AI on top of fragmented observability tools and ensures you are not trading AI efficiency gains for AI cost sprawl.
AI SRE for the Enterprise
Organizations needing extensibility can create customized agentic workflows using the Observe MCP Server, which leverages Observe’s knowledge graph to provide AI agents more context on observability data for greater accuracy. You can create custom agents, which bring in proprietary data and other business context, to meet your unique enterprise requirements. You can also connect agentic tools, such as Cursor, Claude, and Augment, to explore your telemetry from those environments.
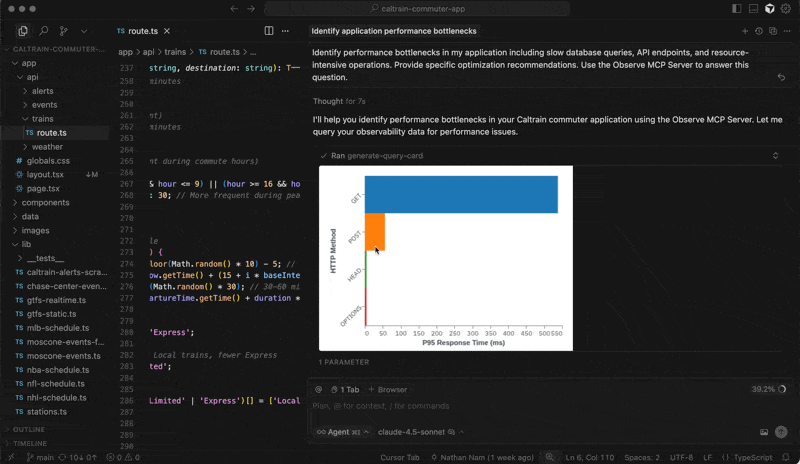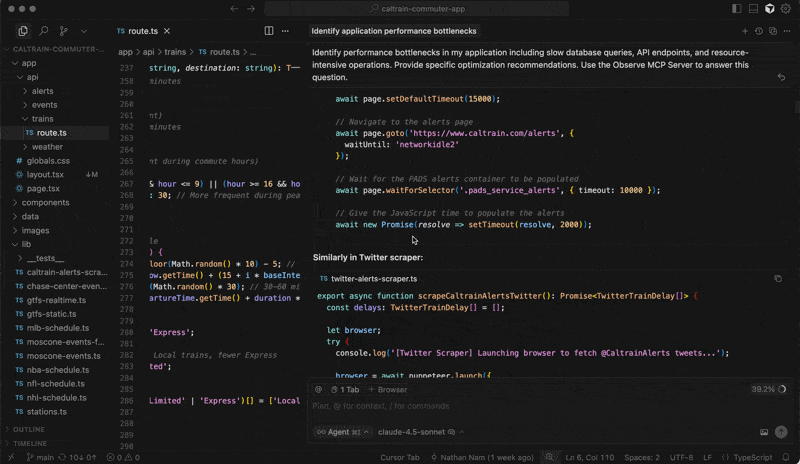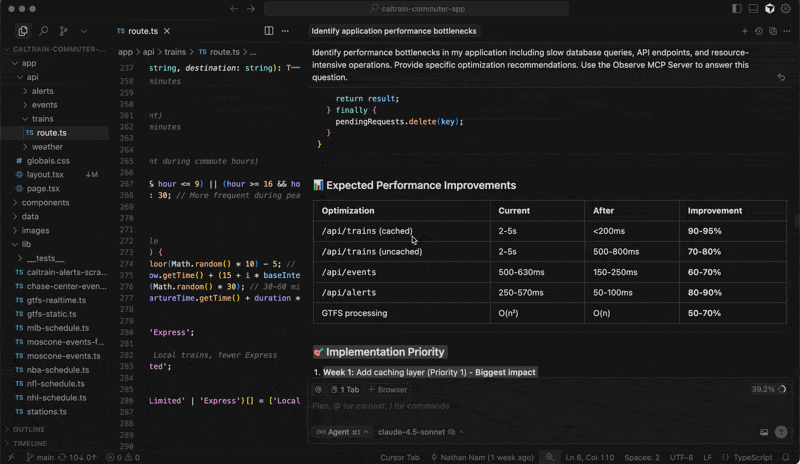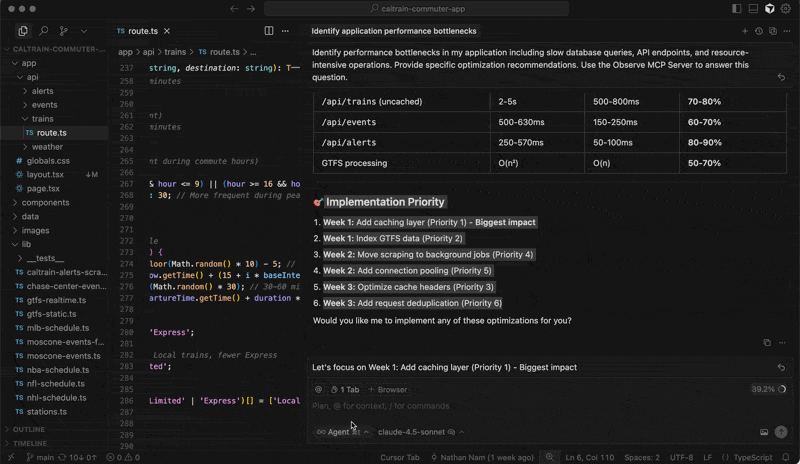
And because the AI SRE runs on the Observe platform, it inherits built-in privacy, security, and compliance controls, including role-based access control (RBAC), SOC 2 Type II, ISO 27001, and GDPR support, allowing AI-driven observability to scale in enterprise environments.
See How AI SRE Makes You More Productive
By cutting through noisy data, finding root causes fast, and recommending targeted fixes, the AI SRE takes on much of the busywork that slows SRE teams down. Built on Observe’s scalable platform, it scales with you without unwanted costs or complexity.
To try the AI SRE for yourself, log into your Observe account or contact your account team to learn more.
→ View our virtual event, Future of Observability: How AI Agents Are Shaping Reliability Engineering, with Observe CEO, Jeremy Burton, and Augment Code CTO, Igor Ostrovsky.
