

Observability at Scale

If you've been to our website recently you might have noticed that its changed. Yes, there is now plenty of talk about AI - I've spent enough time in Italy to know that you don't fight fashion. Less fashionable, but arguably just as important is the ability to solve Observability problems for our customers at 'scale'.
What do we mean by 'scale' ? Many things.
- We ingest tens or hundreds of terabytes of telemetry data into a single instance of Observe. And we'll do it 24x7x365 handling almost anything you can throw at us.
- We store all that telemetry in an S3-based data lake so its cheap as chips. We compress the data on average 10x and store it in Apache Iceberg format so you're not locked in.
- When there's an incident and everyone jumps onto Observe to troubleshoot we won't kick users off the system and queries will not grind to a halt. Our system concurrency is amazing.
- As a matter of course, we'll deliver >99.9% availability and - through our 'platinum resiliency' option - we'll give you failover to another availability zone with RTO of 15 minutes.
- We don't care about the cardinality of your metrics - we'll just handle it. Unlike most observability tools we do not build indexes for each discrete time series.
- We allow you to filter out your unwanted logs (without buying a separate pipeline tool) and sample your traces as much - or as little - as you want.
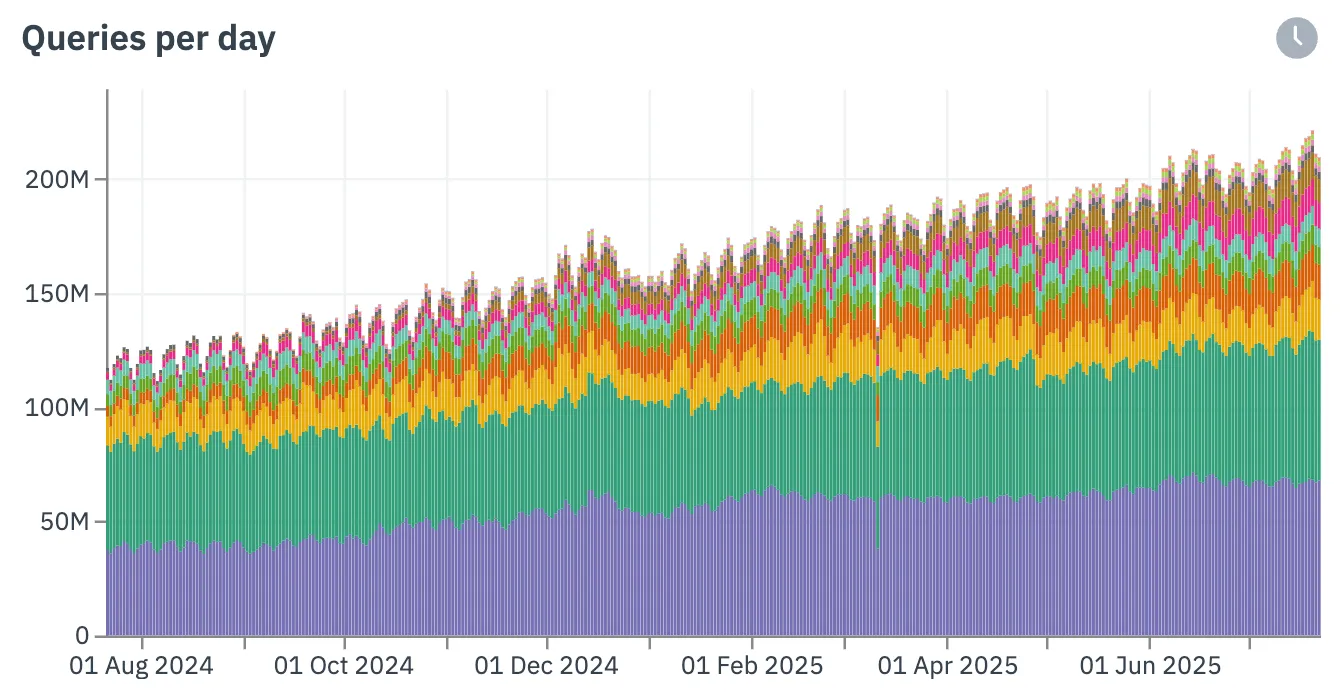
In our production clusters we execute about 220M queries per day on average, ingest around 1PiB/day and scan around 16PiB/day Our largest customer is less than 5% of that query volume, so no matter how much data you have... and how much you want to query it, we can handle it
If you are operating at scale and have issues with cost, availability, cardinality or concurrency then we'd like to talk to you. Observability at scale is our business.

