
Enhancing Regulatory Compliance through Observability
 By Jack Coates,May 7, 2024
By Jack Coates,May 7, 2024
Businesses and government agencies have been facing growing requirements for Observability data. It is often the only way to see exactly what is going on inside modern IT systems and the volume of data is increasing at an alarming rate.
To make matters worse, compliance auditors are increasing requirements for data retention, especially around logs; in the US Federal Government, Memorandum 21-31 starts with a year of retention of logs and moves towards a year of retention for systems telemetry as well. In other industries, regulators are insisting on data classification, retention and deletion over varying time periods. Data may need to be kept for 1 year (PCI DSS, NISPOM) to 3 years (ISO 27001, NIST), to 6 years (HIPAA, GLBA) or even 7 years (SOX).
These industry regulations may not always apply to systems telemetry, but other ancillary requirements that support forensic discovery for security, compliance, or operational awareness range from 6 months (VISA CISP, NERC) to 3 or more years (BASEL II). Retaining logs for weeks or months purely for troubleshooting purposes is a fairly high bar, but meeting standards for compliance standards on top of that can be quite daunting.
A common first response to the retention problem is to archive data to long term storage – this used to be the realm of tape storage but in recent times has moved to low cost cloud storage services such as AWS Glacier, S3 or some other form of blob storage. However, this is painful because getting access to the data can sometimes take hours or even weeks. And things get worse if you need to delete data that has found its way into long term storage … no-one wants the data they thought was deleted to show up at audit time. IT teams find themselves lowering storage costs but increasing labor costs due the elaborate and inefficient process for archiving and, later, recovering or “re-hydrating” data. They are quickly realizing that they need a better answer – how can they ensure data is retained (or deleted!) and searched in a timely fashion ?
Observability enables organizations to trace the journey of its data through intricate pipelines from collection to transformation to use… then to retention and, ultimately, deletion. While the primary use case for an Observability platform is to help IT teams troubleshoot problems with modern applications, its cost model, ease of use and interactive interface make it a perfect option in a world where data regulations propagate almost as swiftly as the data itself. A well architected observability platform will not only retain all data for months (or years), the data will always be “hot” – ready to be searched at any time. It will also provide granular role-based access control, and automatically attend to retention and deletion per administrator policy.
Finally compliance use cases tend to be heavy on storage – there’s a lot of data – and light on compute – searches are performed relatively infrequently. The ideal architecture for an Observability platform separates these two components – data can then be ingested to low cost cloud storage and then compute applied elastically when the data needs to be queried.
Observe: A Modern Architecture for Compliance
The Observability Cloud by Observe meets all of the requirements to support a wide variety of regulatory / compliance use cases.
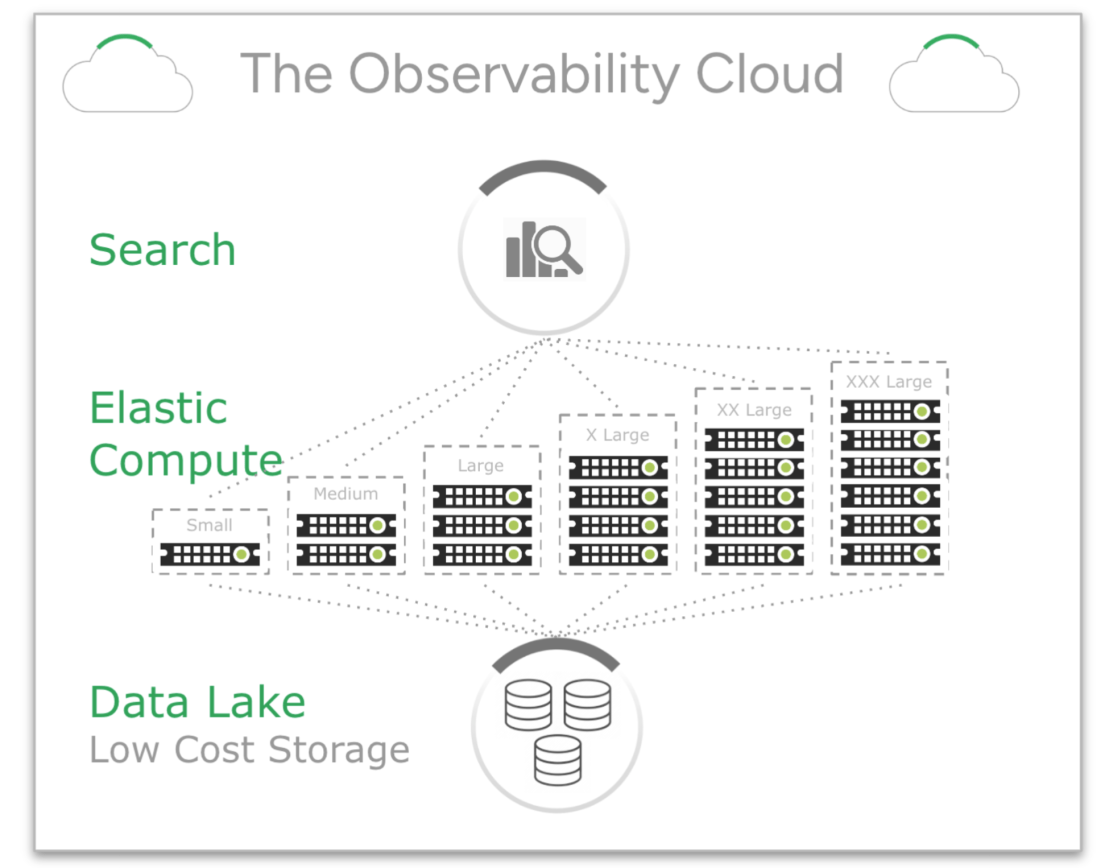
Central to the Observe architecture is a Data Lake, serving as a unified repository for all machine generated data—logs, metrics, traces, or anything else. Data enters the Data Lake via open-source collectors and pre-built integrations and provides default retention of 13 months, for any type of data.
The Data Lake is built on low cost AWS S3 cloud storage, all data is ‘hot’ and ready to be searched at any time. Observe runs on an elastic compute platform and so users only incur costs when they are actively searching the data. This makes Observe the most economic way to ingest, search and retain massive volumes of data for compliance purposes.
Observe’s architecture not only facilitates comprehensive data oversight for auditors and internal compliance teams, at the same time, it can also seamlessly support daily use of that data to solve operational challenges with modern applications and infrastructure.
A Strategic Cost Advantage
The Observability Cloud features familiar ‘ingest-based’ and unique usage-based pricing models. Which is more favorable depends on the use case, however, a typical compliance use case featuring large volumes of data – which must be retained for 12 months or more – with low search volumes naturally lends itself to a usage-based model.
In almost all competitive products, when data is ingested it is indexed so it can be efficiently searched. Since building indexes is compute intensive, it is expensive to ingest data. Next, to provide good search performance, indexes must be stored on high performance storage… making it expensive to retain data for any length of time. Bottom line ? It’s expensive and to lower costs all these products push their users to filter out data, cut retention times and archive data to cheaper storage, which drives up the management burden.
Now let’s contrast that approach with the Observability Cloud. When data is ingested into the Observability Cloud it does not create indexes. This is because the Observe search engine does not require indexes to search efficiently, which makes ingesting data inexpensive. In addition, all data is stored in low-cost cloud storage and is compressed around 10x, which makes retaining data – even for long periods of time – inexpensive. Finally, when users search they consume compute – which can be expensive – but compute is elastic, enabling customers to be billed only for what they consume. And the best bit ? There’s no need to filter data, cut retention times or move data to cheaper storage… in fact, there is zero management overhead.
This strategic cost advantage plays a pivotal role in addressing the unique requirements of compliance, enabling organizations to maintain comprehensive audit trails over extended periods of time without blowing their budget. And it takes on heightened significance in security use cases, where heavy compute usage is a common requirement for normalizing data.
Cloud-Ready Compliance Assurance
Our State of Observability and State of Security Observability surveys have documented a clear trend: the paradigm shift to Cloud deployment models and modern distributed architectures has been rapid, thorough, and is nearly complete in some sectors. Many enterprises operating within regulated sectors have embraced Cloud services, and the introduction of FedRAMP and StateRAMP standards have made cloud services possible for government agencies as well. These changes necessitate greater caution in maintaining compliance with the stringent functional and non-functional data safety requirements imposed by governments and regulatory bodies.
Even in non-regulated industries, organizations increasingly use Service Level Agreements (SLAs) and Key Performance Indicators (KPIs) to manage their own performance. Observability has emerged as a powerful tool to verify KPI conformance with SLAs as well as compliance requirements, aligning seamlessly with the shared goal of meeting predefined criteria. As data regulations and deployment models continue to evolve, the role of observability in supporting regulatory compliance is becoming indispensable.
Leverage Those Compliance Requirements
The volume of Observability data has increased dramatically over the past few years as organizations make the move to cloud-based applications and infrastructure. At the same time, regulators or internal compliance teams are driving IT teams to retain that data for longer. This is resulting in a budget crisis – IT budgets simply cannot stretch to accommodate incumbent tools and their out-dated pricing models.
The Observability Cloud by Observe features a new, unique, approach. The Observe architecture separates storage and compute, enabling data to be ingested into low-cost cloud storage.
To learn more about Observe:
- Visit our website at www.observeinc.com
- Follow us on LinkedIn, Twitter or YouTube
- Sign up for a free trial.