Why Observe – Part 3: The Platform
 By Jacob Leverich,October 12, 2020
By Jacob Leverich,October 12, 2020
In Part 2, I ended by describing the concept of Resources, and how links to Resources can be registered at any time.
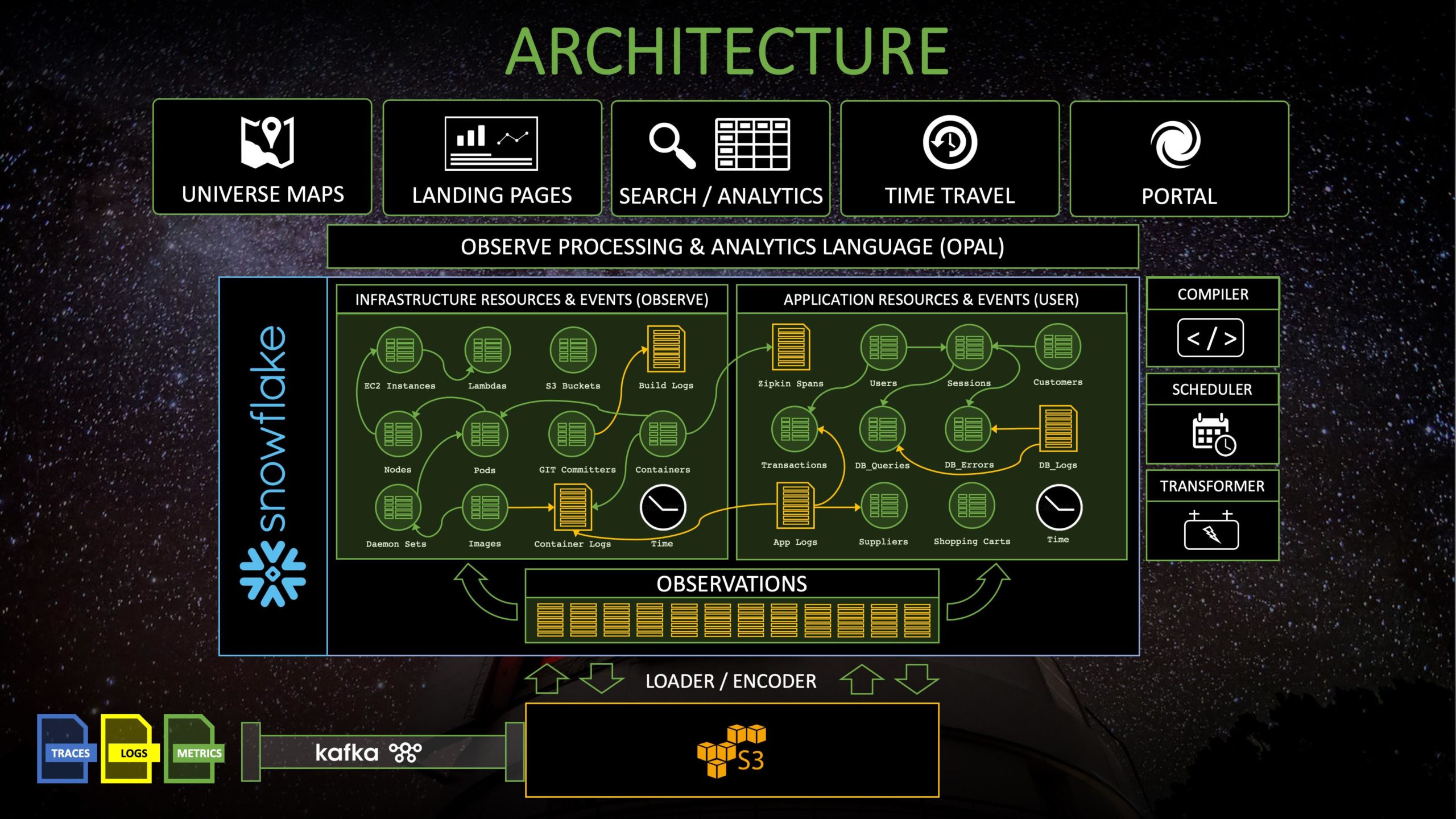
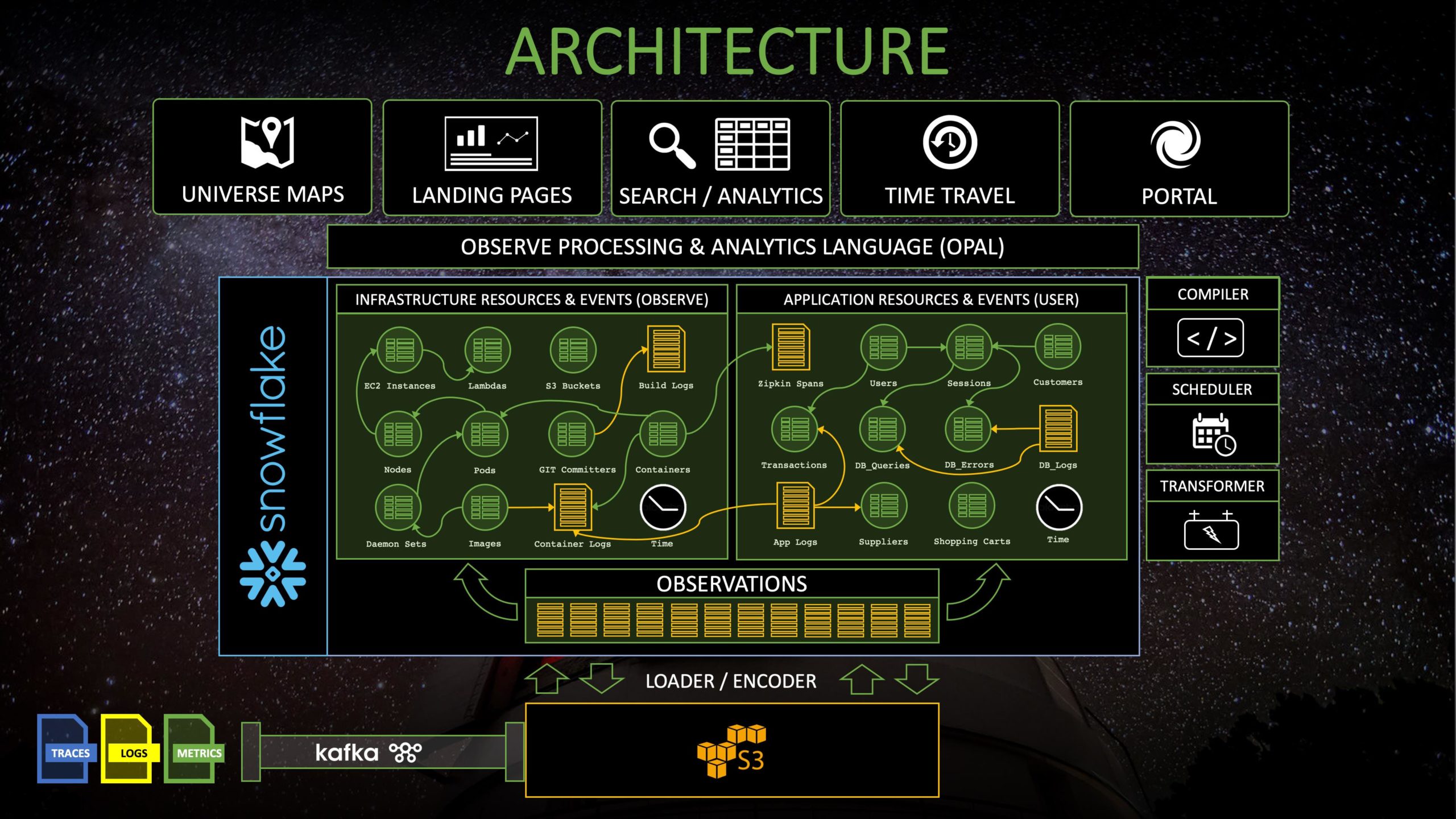
The trick we use to add these links after-the-fact is rather simple: they are simply foreign key relationships in our data model. In fact, our whole solution is built on a foundation of relational modeling of machine data. Perhaps the easiest way to think of this is “We make a relational database out of all of your machine data.” I mentioned in Part 1 that we were rather taken with the OpenTracing data model when we started, and had imagined shaping our product around it. Nevertheless, we found that data model too restrictive and ineffective when trying to represent things that didn’t map tidily to a typical remote procedure call graph (like the changing state of a long-lived Resource). Instead, we found much more joy when we hewed closer to classic relational modeling, or perhaps a model roughly summarized as a “temporal relational star schema for machine data,” This held both for achieving the semantics we wanted out of our query and data management engine, as well as efficiently realizing it.
We make a relational database out of all of your machine data.
All told, this inclination towards relational modeling of machine data led us towards perhaps the most radical decision to date with respect to how to build our product: to use Snowflake (the elastic cloud data warehouse) as the data store of record for Observe. With decades of collective experience building large-scale distributed data management systems in our founding team, it was a rather non-obvious decision to delegate this key piece of our value-delivery chain. Nevertheless, that experience also gave us the collective wisdom to appreciate that it takes 3-5 years of effort to bootstrap a new data management system, which is a rather significant side quest when building a new product! This was especially the case for us, as our product and technical vision relied upon the capacity to do large-scale parallel joins in order to correlate the mountains of disparate telemetry we collected.
The decision to delegate essentially boiled down to this: if there exists a relational database that can satisfy our requirements, we should use it, and we should focus our collective effort towards building a great Observability product instead of building another database. Those requirements came down to:
– Ability to ingest 100s of terabytes to petabytes of data per day, and store those for months to years.
– Ability to provide a delightfully interactive user experience, despite managing terabytes of data.
– Ability to work efficiently with semi-structured data (i.e. the messy slop you find in logs).
– Ability to efficiently execute the kinds of band-joins and window analytic functions needed for us to realize efficient queries on Resources.
– Unit economics that make sense for the Observability use-case.
We started with a bias towards Snowflake, which is not surprising given that two of our co-founders were members of the early engineering team at Snowflake (and built a chunk of its backend execution engine). Even so, it still wasn’t obvious that Snowflake would satisfy all of our requirements above. We spent the better part of our first year as an engineering team ironing out the details, enacting proof-of-concept tracing, metrics, and logging use-cases on top of Snowflake in order to learn where the major challenges lie, all the while carefully accounting for the costs of delivering our solution. Around the time we cracked the puzzle of implementing all of the main operators and semantics of temporal relational algebra on top of Snowflake, we had gathered enough experience, evidence, and conviction that we could deliver a first-class Observability experience on data stored in it, while retaining a competitive price point. We were committed, and the benefit to us was clear: we would be able to focus our engineering attention on product development, and we could rely upon the expressivity of a complete SQL database in our foundation.
I earlier described this decision to vendor our data management system as “radical”. What I mean by this is that many other vendors that have come up in the past couple of decades in the monitoring and Observability space have gone out of their way to build custom data management systems, tailored to excel at some particular shape of data or access pattern for those data (e.g. fine-tuned columnar compression of time-series metrics, keyword indexing of logs, in-memory streaming processing, etc.). The benefit for these vendors is the opportunity to claim superlatives about those use-cases: like “blazing fast search!” or “alerts in milliseconds!”. By basing our product on a more general purpose data platform, we will probably miss out on early opportunities to claim those same superlatives. That notwithstanding, we believe our ability to shape and contextualize any sort of machine data will lead to a better “Observability” product altogether, and will allow us to continue stretching the product into all the nooks and crannies of a business as time goes on.
Apart from the opportunity to focus our attention on building a great Observability product, basing our solution on Snowflake led us to another seemingly unconventional decision that we have since developed strong convictions about. Snowflake is a cloud-based data warehouse, and is not available to run on-prem or on your own servers. Consequently, our solution is “cloud-only” as well, and we do not anticipate offering an “on-prem” solution in the foreseeable future. We initially had some concerns that this would harm our ability to attract customers who are used to running their monitoring and Observability stack in-house. These concerns have not borne out: this has rarely come up as a roadblock in our conversations with customers, and the breakout success of Datadog (and even Snowflake) has spoken volumes about the appetite for turn-key SaaS solutions for monitoring (and data management) in modern enterprises. That being said, we’re more than happy to follow wherever Snowflake goes, which fortunately means portability amongst all of the major IaaS providers.
As a last unconventional decision to share, we’ve always imagined from our inception that we would enter the market with a usage-based pricing model. That is, rather than charging a premium to ingest data (whether metered by GBs/day or number of host agents or custom metrics or whatever), it has always been our assumption that we would make it dirt cheap to shovel data into Observe. Instead, our bargain is essentially that we would charge customers a premium only when they are getting value out of their data (like actively troubleshooting or consuming a dashboard), and not just for the privilege of storing machine data. In turn, this means that our all-encompassing goal is to make the data managed by Observe as meaningful and actionable as possible, so that our customers seek it out on a daily basis. This approach to pricing presents business risk to Observe, but the outcome is that our incentives are aligned with our users: our goal is to make their machine data as valuable and useful as possible, so that customers spend quality time using it in Observe. For us, the focus on achieving this outcome is worth the risk.
Around the time this story is published, we will have officially come out of stealth and launched Observe, Inc. We’ll have many more stories to tell in the near future about our offering, and many deeper dives into the technology that makes Observe unique. Reflecting back on the journey that brought us here, I reminisce most on something our co-founder Jon Watte once said, which is “This is the product that I wish I always had, and now I actually get to build it.”
For all of us on the Observe founding team, our passion for Observe is rooted in our experiences in fire-fighting issues in large systems, and in trying to tell meaningful stories with machine data. We hope it can help you on your own journey to achieve “Observability”.