
Observe: The Journey Continues
 By Jeremy Burton,May 11, 2022
By Jeremy Burton,May 11, 2022
Growing Like A Weed
Time flies, doesn’t it?
When we rolled out our last public announcement we had approximately 20 customers. Today we’re approaching 50 customers and have seen a 5x increase in the number of monthly active users along the way.
I’m always proud to talk about Observe – first and foremost – as a ‘Data Company’. So maybe the best way to chart our success so far is to look at the data. To date, we’ve ingested over 10PB of data – now averaging 40TB per day – and by the time that data is stored and compressed it totals around 1PB. This data will continue to stack up because, unlike most in the observability space, we keep data for 13 months by default – a huge benefit of our modern architecture.
Making The Most Of Your Data
But data is not useful if it is simply ingested and stored. Customers really benefit when data is analyzed, understood, and acted upon. To that end, we execute around 2.5M queries each and every day – which is about 1% of Snowflake’s daily query volume! In a month that translates to 27,000,000,000,000 (that’s “trillions!”) rows scanned across 10PB of data. And we’ve really only had customers using Observe in anger for just over a year – we’re just getting started!
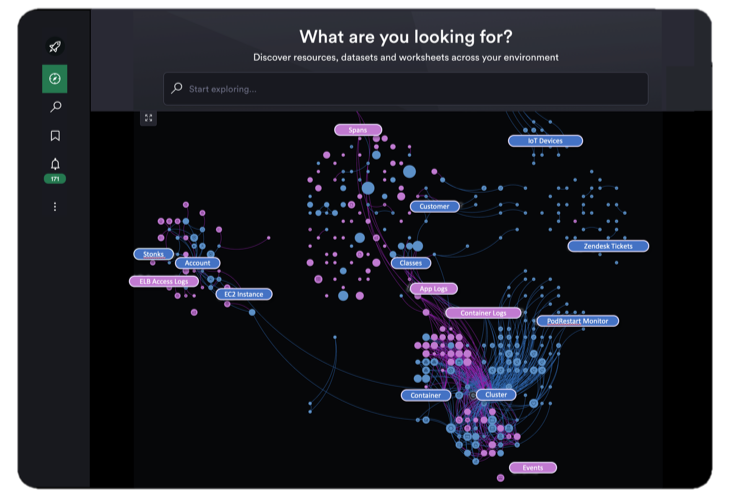 Observe’s capabilities have kicked on massively over the past twelve months – so much so, that I can’t possibly list them all here. Core to our differentiation (i.e. our “secret sauce”) is our ability to transform machine-generated data into a graph of connected datasets, understandable by humans. Because of this, bringing relevant context to bear immediately on any incident or investigation is simple. Much of what we introduced today doubles down on our core differentiation. For example, our dataset graph can now be visualized and explored, and our dashboards are context-sensitive enabling users to drill down in context to the underlying event data. Everything in Observe is connected.
Observe’s capabilities have kicked on massively over the past twelve months – so much so, that I can’t possibly list them all here. Core to our differentiation (i.e. our “secret sauce”) is our ability to transform machine-generated data into a graph of connected datasets, understandable by humans. Because of this, bringing relevant context to bear immediately on any incident or investigation is simple. Much of what we introduced today doubles down on our core differentiation. For example, our dataset graph can now be visualized and explored, and our dashboards are context-sensitive enabling users to drill down in context to the underlying event data. Everything in Observe is connected.
In addition, we’ve also done quite a bit of work on making sure that users can immediately observe common environments such as Kubernetes, AWS, GCP, and Jenkins. We have packaged content – datasets, dashboards, and alerts – which just light up when telemetry data is flows Observe. This saves everyone time and allows the focus of observability to be on the application, not the infrastructure.
Funding Update
Today we’re also talking about our most recent funding. We continue to be delighted by the support we receive from Mike Speiser at Sutter Hill Ventures. Building Enterprise Software is not easy – the barrier to entry is high and it takes time. Mike’s long-term view of a company’s prospects and the difficulty in unlocking established markets is critical to our success.
 In addition, I’m also delighted to welcome Capital One Ventures as an investor in Observe. I am very familiar with Capital One from my time serving on the Snowflake Board of Directors – they were an early investor in Snowflake and did a wonderful job of making the early product successful. My hope is that we can follow in Snowflake’s footsteps and establish Capital One as one of our largest customers.
In addition, I’m also delighted to welcome Capital One Ventures as an investor in Observe. I am very familiar with Capital One from my time serving on the Snowflake Board of Directors – they were an early investor in Snowflake and did a wonderful job of making the early product successful. My hope is that we can follow in Snowflake’s footsteps and establish Capital One as one of our largest customers.
Speaking of customers, we realize that as a new company we have to earn our right to their business each and every day. We almost always start small – like really small – with initial commitments often being less than $5000. We prove our value and then, based on that, we look for more commitment. That’s the beauty of our usage-based pricing model – the customer only pays when they are using Observe…and if our service is being used, then the value is clearly there.
Pricing is always on the minds of our prospective customers, in part because data volumes grow 40-60% each year – and because most pricing models are a proxy for data volumes, their bills grow approximately 40-60% each year. We believe that Observe’s modern architecture is fundamental to addressing this issue. By our calculation, users should be able to have their data volumes grow 5x before seeing this level of increase.
What’s Up Next?
We really want to build out more tracing visualizations as we have some users today who work with OpenTelemetry data but they do so with our scripting language, OPAL. It’s clearly still early days for OTel – and distributed tracing in general – but it’s definitely one for the future.
If you want to know more about these exciting updates at Observe please check out our launch!